图注意力神经网络:《graph attention network》阅读笔记

abstract
提出图注意力网络,一个新的基于图结构数据的神经网络构架。借助注意力层来克服图卷积操作的短处。
节点可以参与到邻居节点的特征。
introduction
卷积操作适用于grid-like structure,卷积网络的构架高效地重复使用local filters。
但是对于别的情况,比如3D meshes, 社交网络,生物学网路来说,他们并不是grid-like data。
已经有一些尝试将神经网络应用在任意结构的图(相比于grid like structure)上。
目前,研究者对使用卷积操作到图领域这件事非常感兴趣,分为两类spectral approach和non-spectral approach。谱方法和非谱方法。
(#TODO: 对于图上卷积操作的review)
本文提出一个基于注意力机制的节点分类方法:computing hidden representations by attending over its neighbors following a self-attention strategy.
具备以下几个优势:
- 操作非常高效,parallelizable;
- 可以适用于具有不同度的节点;
- 模型适用于 inductive learning problem,包括使用在其他图上。
GAT architecture
在此描述一层GAT。
输入N个节点与其节点特征:h=[h_1,h_2,...,h_N], h_i \in R^F
输出N个节点与其节点特征,其特征维度更新到 F' ,h'=[h'_1,h'_2,...,h'_N], h'_i \in R^{F'}
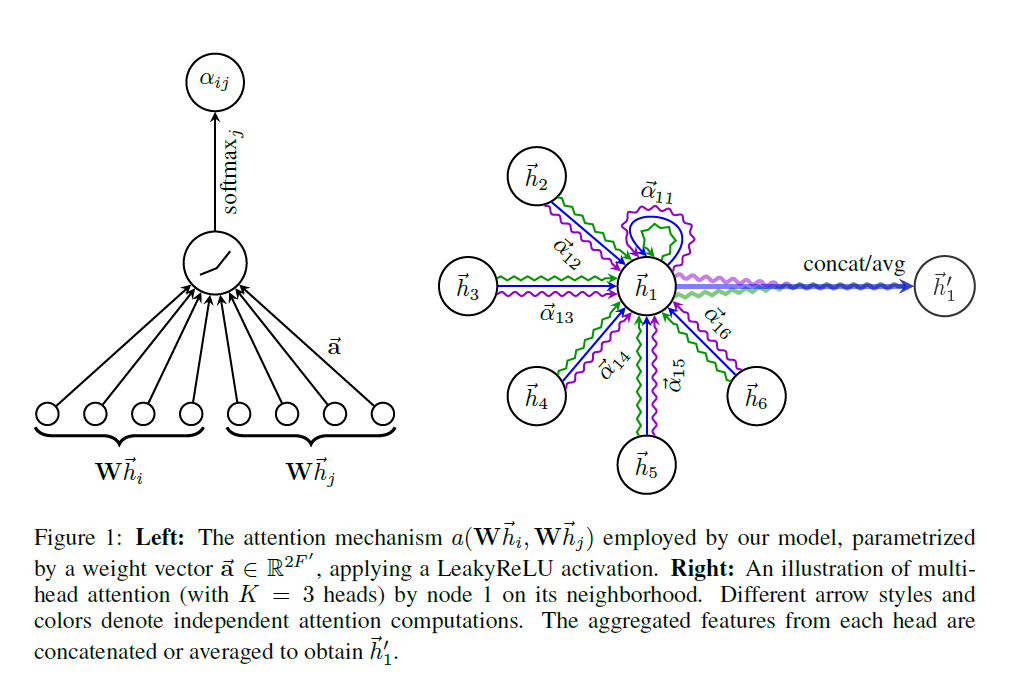
在这一层中,包括一个共享的注意力机制:a: R^{F'}\times R^{F} \rightarrow R 。
这代表的是对于j节点对于i节点的重要度,使用masked attention,只计算 e_{ij} for node j\in \mathcal{N_i} ,准确地说是一阶的邻居节点。
为了使系数方便比较,将重要度归一化为一个标量:
在本文,a是一个单层神经网络,所以综合写为:
计算图如左图所示:
计算完每个边上的“注意力”后,使用一个非线性变换进行更新节点:
为了稳定学习过程,可以将增加多头注意力,如上图的右图,就是三头注意力。
应为有K个head,所以得到的h'_i 的长度为 KF',为了避免这种情况,可以让K个head的F'长度的向量取平均值。
个人总结
- GAT并不使用edge attribution;
- 适用于节点分类任务。
pyG实现

显然,我们只需要定义好F,和F',就可以初始化一个注意力图神经网络了。